In this post I would like to dive into the rabbit hole of sprite records. First, I will provide a short overview of sprite demos, to then share my journey towards SMFX's latest sprite record achievement; drawing 268 sprites, and concluding look at the path ahead to usurp Oxygene as the current record holder.
Some of this stuff is technical, and assumes knowledge about the basics of the Atari ST machine, such as the organization of bitplanes.
Sprite Introductions
It is an undisputed truth that the Atari ST gets the best out of coders. No dedicated hardware, just the CPU and a frame buffer! Some call it Spartan, others name it Power Without The Price, and a select few say `challenge accepted'!
Apart from the Atari scene, sprite record challenges are nowhere to be found. Of course, we are all familiar with some of the sprite demos on other platforms, like on the Lynx for example; but these are just a tongue-in-cheek reference to its Atari origins. And thus, we, the Atari people should be proud that we are the sole origin of this demoscene classic. We all know that competition brings out the best of us!
Its origins date back to the late 80's early 90's when Atari coders were showing off technical skills. The first ever sprite screen as such was released by the CareBears in the SoWatt demo. It features the famous Mad Max S.O.S. track, that has since been heard over and over on many of the modern sprite record demos. They managed to display 134 sprites in a VBL. (youtube/pouet)

People took note of this kind of technical achievement and started coding their own, trying to beat the record. And of course, the envelope got pushed time and again in the following years. It wasn't until some 10-15 years later that Leonard of Oxygene announced on the atari-forums in august 2004 a little contest and challenge that was inspired by the original sprite demo. This was also the first time, that the rules were made universal for all contestants; which were:
- Must run on plain 520ST
- Must have a 5px high scroller
- Must have a chiptune running
- Must use the same sprite as the SoWatt demo
- Must have background
And later that year, results went up as high as 312 sprites per VBL! A quick search over the demo-databases give me the following results: History of Atari demos (combined results of dhs.nu, demozoo and leonard's sprite record page).
Atari sprite records - A Quick Overview
From digging the sites, I've compiled the following list; categorized as
- Atari records outside the set compo rules
- Atari records following Leonards challenge
- Non Atari platform Sprite record references
Atari records outside the set compo rules
| Name (and link) | Group | Sprites | Date | Note |
|---|---|---|---|---|
| Sprite Record (preview) | Carebears | ~120 | ? | - |
| Sprites Record (134) | Carebears | 134 | 1989-12 | - |
| Delirious Demo 2 | Overlanders | 136 | 1990-04 | 16x14! |
| Overdrive Demo | Phalanx | 143 | 1990-08 | - |
| Digi Composer v2.0 | Istari | 142 | 1991-03 | - |
| The O Demo | Oxygene | 206 | 1992-05 | No bg |
| A New GFA Basic World Record | Oxygene | 38 | 1993 | GFA |
| Libraire Intro #02 | Sector One | 270 | 1993 | No bg |
| Sprites Demo | Oxygene | 165 | 2000-12 | - |
| Optimize Night And Day | Oxygene | 197 | 2001-08 | - |
| Optimize To Death | Oxygene | 212 | 2002-05 | - |
| Sprite Record | Spice Boys | 270 | 2002-07 | Fake,1MB |
| Definitive Revenge! | Oxygene | 220 | 2002-09 | 520ST |
| 271 16x16 SoWatt Sprite Record | Oxygene | 271 | 2002-09 | 1MB |
| 360 Sprite Record | Gwen | 360 | 2002-11 | Fake |
| Limited | P. Simoes | 2000 | 2004-09 | Fake |
| Sprite Record (250) | Phantom | 250 | 2004-10 | No bg |
| Panic | P. Simous | 70 | 2004-12 | Fullscreen |
| 300 Sprites Record | Supremacy | 0 | ? | Fake |
Atari records following Leonards challenge
| Name (and link) | Group | Sprites | Date |
|---|---|---|---|
| Leonard -Definitive- Sowatt Sprite Record | Oxygene | 268 | 2004-08 |
| Sprite Record (221) | Phantom | 221 | 2004-11 |
| 238 Sprites | ULM | 238 | 2004-11 |
| Sprite Record (269) | SOTE | 269 | 2005-02 |
| Sprite Record (270) | Phantom | 270 | 2005-02 |
| Sprite Record (271) | Phantom | 271 | 2005-02 |
| Sprite Record (280) | Phantom | 280 | 2005-02 |
| Leonard -new- Sowatt sprite record | Oxygene | 312 | 2005-03 |
| Industrially Safe 93 16x16 Sprite Record Demo | Effect | 93 | 2015-04 |
| Spkrites! | SMFX | 268 | 2018-11 |
Non Atari platform Sprite record references
| Name (and link) | Group | System | Sprites | Year |
|---|---|---|---|---|
| Sprite Record | Oxygene | Windows | ? | 2001 |
| Garcimore aime les balls | Arkos | Amstrad CPC | 20 | 2004 |
| Maurice aime les bobs | Megachur | Amstrad CPC | 26 | 2006 |
| Boules et Bits | Vanity | Amstrad CPC | 42 | 2006 |
| Eighteen | Dekadence | Amiga | 352 | 2015 |
| New View 48K | Conscience | ZX Spectrum | 42 | 2015 |
| 30 Years Amstrad Megademo | P.Corrosivo | Amstrad CPC | 46 | 2016 |
| Sprite Record (Pico-8) | Dekadence | Pico-8 | 614 | 2016 |
| 어쩌라고 | Limp Ninja | Sega Megadrive | 313 | 2016 |
| Sprite Record | DTA | Sam Coupe (8bit) | 18 | 2018 |
| Sprite Record (Lynx) | Dekadence | Lynx | 192 | 2018 |
Why did I care?
Over the years, a lot of sprite demos have been made; and it was not until this year that I myself started coding a specialized sprite routine for a certain type of screen I had in mind. I needed a fast sprite rout, and was tired of the same old generic cookie-cutter approach to mindlessly shift the graphic/sprite in 16 places, to subsequently copy the buffer depending on the x-position the sprite was at.
So I set off to start coding a sprite generator for my specific need. I wanted to keep track of how different approaches would compare to each other so; so I initially decided to code the different algorithms in a same code-file for benchmarking, so results could be easily compared to each other. I would like to share with you some of my found results and explain the approach/code used to get these results.
For all intends and purposes I assume a 16x16 two bitplane sprite for code snippets and examples; and only list code relevant for the sprite drawing method. The sprite used in my initial benchmark code is the same as in the Sprite Demo, and is as follows:
For general curiosity and comparison sake, I also list my results for 1 bitplane sprites and 32x32 sized sprites; since I was also curious as to how these different factors would relate to each other over different sprite codes.
Case 1 - Copy from buffer
This was my generic goto situation that I have been using in my demos for the past years. Its fairly easy; you can lay out the code, select source data and target position, and just copy it in. One piece of code to fit all the 16 cases, by taking the bounding box of all 16 positions of the sprites, and copy the data.
You get something along the lines of:
; given:
; a0: selected shifted sprite source, based on x-position of the sprite (0..15)
; a1: screen address with incorporated x,y displacement on 16 pixel boundary
.y set 0
REPT 16 ; 16 lines
.x set .y
REPT 2 ; spriteWidth defined as blocks of 16 pixels (1 block), +1 for block for the shifted sprite
move.l (a0)+,d0 ; read 16 pixels, 2 bitplanes from source data
or.l d0,.x(a1) ; or.l the
.x set .x+8
ENDR
.y set .y+160
ENDR
The clearing code is similar to the above, but instead of reading the buffer, we just move a zeroed out register in:
; given:
; d0: register value 0
; a1: screen address with incorporated x,y displacement on 16 pixel boundary
.y set 0
REPT 16 ; 16 lines
.x set .y
REPT 2
move.l d0,x(a1) ; clear the 16 pixels for 2 bitplanes
.x set .x+8
ENDR
.y set .y+160
ENDR
This would yield ~92 sprites per vbl. Of course, reading the buffer can be further optmized with using movem.l (a0)+,d0-d7, speeding up the reading from the buffer part of the algorithm. This will win you a few more sprites (in my measurements, I would hit 95). Its clear that even if we optimized the outer loop code, it will be a stretch to get 100 sprites on screen while we got music playing.
Case 1 Result
| Result | 16x16s | 32x32 |
|---|---|---|
| 1-bpl | 130 | 44 |
| 2-bpl | 92 | 31 |
A very course estimation would come down to: 1740 cycles per sprite.
Case 2 - Generate code from buffer, and use immediate operations instead of copying from buffer
This was the first step that I could think of. Instead of being mindlessly generic, lets be more specific! And thus instead of just using the sprite source buffer for drawing, use the sprite buffer to generate code. In this case, we can easily omit copying/drawing empty data from the buffer. Thus, when reading from the buffer to generate the drawing code, we omit empty words. (E.g. an empty longword is ommitted for drawing completely in the generated code, and an empty word in a longword results in only drawing the appropriate word).
It results in 16 specificly generated draw routines for the sprite. Code generation is done as follows:
; given:
; a0 selected shifted sprite source
; a1 generated code buffer
; d0 ori.w #$xxxx,z(a0)-operand in top word
; d2 screen offset
; d3 ori.l #$xxxxyyyy,z(a0)-operand in low word
genSprite macro ; code to generate the operations for a single 16-pixel, 2 bitplane block
move.w (a0)+,d0 ; get top word from buffer
beq .skipFirst\@ ; if its value is 0, skip the first word for drawing
;--------------- top word filled
move.w (a0)+,d4 ; get low word from buffer
beq .firstFilled\@ ; if its value is 0, only the top word has to be drawn
.bothFilled\@ ; if its value != 0, then both words need to be drawn, using ori.l
move.w d3,(a1)+ ; operand ori.l #$xxxxyyyy,z(a0) operand
move.w d0,(a1)+ ; top word $xxxx
move.w d4,(a1)+ ; bot word $yyyy
move.w d2,(a1)+ ; word offset into screen, z
jmp .skip\@ ; end of
.firstFilled\@ ; this
move.l d0,(a1)+ ; operand .w + top word
move.w d2,(a1)+ ; word offset
jmp .skip\@
;--------------- end top word filled
.skipFirst\@
move.w (a0)+,d0 ; get the low word from buffer
beq .skip\@ ; if its value is 0, then we skip drawing this 16 pixel block
;--------------- lower word filled
move.l d0,(a1)+ ; operand .w + low word
move.w d2,(a1)+ ; offset
add.w #2,-2(a1) ; offset correction +2, because its the lower word only
jmp .skip\@
.skip\@
endm
Generated code for a single sprite (position x=0):
; given
; a0: screen address with added compound x,y offset
ori.w #$7e0,0(a0)
ori.w #$1ff8,160(a0)
ori.w #$3ffc,320(a0)
ori.w #$7ffe,480(a0)
ori.l #$63fe1c00,640(a0)
ori.l #$c1ff3e00,800(a0)
ori.l #$b8ff7f00,960(a0)
ori.l #$b8ff7f00,1120(a0)
ori.l #$b8ff7f00,1280(a0)
ori.l #$b8ff7f00,1440(a0)
ori.l #$c1ff3e00,1600(a0)
ori.l #$63fe1c00,1760(a0)
ori.w #$7ffe,1920(a0)
ori.w #$3ffc,2080(a0)
ori.w #$1ff8,2240(a0)
ori.w #$7e0,2400(a0)
A quick generalized comparison of case 1 and case 2 yields:
move.l (a0)+,d0 ;12
or.l d0,x(a1) ;24
-----> 36 cycles per 2 bitplanes/16 pixels
versus
ori.l #$12345678,x(a1) ;32
So even worst case, on every 16 pixels, 4 cycles are won. And this improvement is independent on the sprite; whereas the benefit of skipping drawing, or drawing .w instead of .l are depending on the sprite instance.
Adapting the clearing routine for this does not yield any improvement, considering it is done by registers. However, by generating the clearing routs for each of the 16 shifted positions, the benefit of omitting clearing pixels if they are not drawn, or clearing words instead of longwords gives some speed enhancements. This makes sense of course, since we now have 16 clearing routines specifically tailored to the shifted sprite; which is generally a smaller area than the previously naively determined bounding box.
Case 2 Result
| Result | 16x16 | 32x32 |
|---|---|---|
| 1-bpl | 145 | 60 |
| 2-bpl | 136 | 49 |
A very course estimation would come to around 1180 cycles per sprite.
Case 3 - Generate code, but analyse the buffer and use load values that are duplicated to registers, per sprite
One of the cases that begs for optimization is when the sprite is mirrored vertically. As we can see from the generated code in Case 2, all the masks are used at least once, and in the middle of the sprite, the same mask is used 4 times. In practice this means that you can guarentuee that every 16 pixels you have to draw, will have to be drawn twice, but on different offsets. Generalized this means, that every 16-pixel mask that needs to be drawn 2 or more times should no longer be drawn using ori.w/ori.l but instead loaded in a register then then drawn multiple times using the preloaded register.
Generalized; case a vs case b
; case a
move.l (a0)+,d0 ;12
or.l d0,x(a1) ;24
or.l d0,y(a1) ;24
-----> 60
; case b
ori.l #$12345678,x(a1) ;32
ori.l #$12345678,y(a1) ;32
-----> 64
So instead of directly converting the preshifted sprite buffer to code as in case 2, we first analyse the masks in the buffer, and do a count per mask. Subsequently, every mask that is used 2 or more times, is converted to loading as a register, and then drawing to screen.
The approach I took here was to keep track of 3 things per mask:
- mask
- offsets per usage
- nr of offsets (is ofcourse implied by 3.)
Then subsequently, by iterating through this result, it can be determined what code generation path to follow; case a or case b (with a single ori.l obviously...).
Considering this generation code is quite long, and Im not entirely sure how it would benefit this article, I prefer not to list the code here, but instead refer to the published code at https://github.com/spkrsmfx/spkrites/blob/master/sprites.s ; line 995.
The generated code for a single sprite (position x=0) is as follows:
; given
; a0: screen address with added compound x,y offset
move.w #$7e0,d4 ;load mask
or.w d4,0(a0) ;draw mask
or.w d4,2400(a0) ;draw mask
move.w #$1ff8,d4
or.w d4,160(a0)
or.w d4,2240(a0)
move.w #$3ffc,d4
or.w d4,320(a0)
or.w d4,2080(a0)
move.w #$7ffe,d4
or.w d4,480(a0)
or.w d4,1920(a0)
move.l #$63fe1c00,d4
or.l d4,640(a0)
or.l d4,1760(a0)
move.l #$c1ff3e00,d4
or.l d4,800(a0)
or.l d4,1600(a0)
move.l #$b8ff7f00,d4
or.l d4,960(a0)
or.l d4,1120(a0)
or.l d4,1280(a0)
or.l d4,1440(a0)
Note; for clarity in the example and also in my benchmark (because it seemed a pain at that time to implement), I have omitted the possible optimization to use movem to load the used registers. Above code and used code generation lacks this optimization.
As for the clearing routine, we have already found an optimal solution; at least on a per-sprite basis.
Case 3 Result
| Result | 16x16 | 32x32 |
|---|---|---|
| 1-bpl | 160 | 66 |
| 2-bpl | 142 | 54 |
A very course estimation would come to around 1128 cycles per sprite.
As you can see, we're already hitting the Carebears SoWatt sprite record (134) with this code setup. But we're still not getting NOWHERE close to the records achieved following Leonards challenge (220+). So we have to leave the domain of plotting `every sprite individually' and look for the next step.
Case 4 - Generate code, but group sprite drawing per x-shift, read one, write many
The obvious next step on top of our previous case is to group the sprites per case (x=0..15), preload the registers per case, and then draw all the sprites that are of this case. Thus, first draw all sprites that are at the source of 16-pixel boundary (x=0), by loading the sprite data into registers once, and then draw many times; before moving to the next set of sprites (x=1).
The draw code per case is going to look something like this:
; given:
; a0 = screen address
; a6 = dataset containing
; a). offset into unrolled loop (once per sprite partition)
; b). an offset displacement for each sprite, relative to each other; for example offsets y=1,y=3,y=10 is modeled as: dc.w 160,320,1120
; loop_sprites0 = a constant that is the indication of the largest set of sprites being drawn using that method over all frames
lea .sprite0Regs,a5 ; load mask values address
movem.w (a5)+,d0-d3 ; preload the word-sized masks
movem.l (a5)+,d4-d6 ; preload the longword-sized masks
move.w (a6)+,a5 ; get the offset into the unrolled loop, determining the number of sprites to draw for this case
jmp sprite0or_new(pc,a5) ; jump into the jump table
.sprite0Regs
dc.w $07E0 ; $0,$960 .w 0,15
dc.w $1FF8 ; $a0,$8c0 .w 1,14
dc.w $3FFC ; $140,$820 .w 2,13
dc.w $7FFE ; $1e0,$780 .w 3,12
dc.l $63FE1C00 ; $280,$6e0 .l 4,11
dc.l $C1FF3E00 ; $320,$640 .l 5,10
dc.l $B8FF7F00 ; $3c0,$460,$500,$5a0 .l 6,7,8,9
sprite0or_new
REPT loop_sprites0
add.w (a6)+,a0 ; add x,y compound offset to the screen position
or.w d0,(a0) ; draw the sprite per mask
or.w d0,$960(a0) ; draw the sprite per mask
or.w d1,$a0(a0) ; draw the sprite per mask
or.w d1,$8c0(a0) ; draw the sprite per mask
or.w d2,$140(a0) ; draw the sprite per mask
or.w d2,$820(a0) ; draw the sprite per mask
or.w d3,$1e0(a0) ; draw the sprite per mask
or.w d3,$780(a0) ; draw the sprite per mask
or.l d4,$280(a0) ; draw the sprite per mask
or.l d4,$6e0(a0) ; draw the sprite per mask
or.l d5,$320(a0) ; draw the sprite per mask
or.l d5,$640(a0) ; draw the sprite per mask
or.l d6,$3c0(a0) ; draw the sprite per mask
or.l d6,$460(a0) ; draw the sprite per mask
or.l d6,$500(a0) ; draw the sprite per mask
or.l d6,$5a0(a0) ; draw the sprite per mask
ENDR
sprite0
This way we get to load the registers once, and draw them many times, with minimum overhead. The above given example is a simple case, where we have less than 8 values that make up the drawing of the sprite; and there are of course various cases where the number of used masks are beyond the 8 available registers for or.l.
Because this setup requires the precalculation of the sprite positions, as well as categorizing the sprites and determining the relative offsets between subsequent sprites in the same partition; I implemented this approach outside the comparison framework. Somehow I realized that with this approach I was moving towards a `how can I display a precalculated sequence of frames', and starting to interweave the movement data into the display code; that I moved on to a seperate file; that in turn ended up being my first sprite record demo....
If my memory serves me right; this initial approach yielded my first 200+ sprite count result. This would boil down to around 800 cycles per sprite.
And then the optimization bug started to get me...
A Sprite Record Attempt Is Born
Having laid down the format of the `read masks once -> write many' approach, it seemed that there was still a decent gap between the achieved ~200 sprites count using this approach and the 235, let alone the 270/300's. So something has got to give. In order to see what else we can improve on, we have to decompose what is happening.
The general approach for each frame is:
- clear existing sprites
- determine movement
- draw new sprites
We have already completely optimized the pattern movement (2), by incorporatng this into a 16-part dataset (per frame). Where each dataset corresponds to their related (0..15 position) draw masks and unrolled loops. For the sprite record, Leonard defines (and has shared) the code to generate the pattern, which is a 360-frame loop. So precalcing this, and then adapting it for the used code pattern above yields basically an animation that you can use to get the desired datastream.
Since optimizing (2) as a seperate algorithm/concern is out of the question, we are left with finding smarter approaches for (1) and (3).
Optimization of clearing
So far we have been clearing individual sprites. In case multiple sprites overlap, we clear certain areas more than once. This is a waste. This can be easily remedied by analyzing the total area of sprites drawn to the screen, and then building a dataset that is an explicit list of offsets of the screen to be cleared by moveing a longword from register to an indirectly addressed dataregister.
Considering the sprite demo is bound to be using 512kb at the most (since rules state it must run on a 520ST), having 360 datasets which all explicitly clear their accompanied frame-spritepositions is quite space-inefficient. So some tradeoff needs to be made; balancing the size of the dataset combined with reuse of code over multiple frames.
I like to move it, move it!
So far, we have by default chosen to use the or operation for drawing, considering that sprites overlap, and a move operation basically overwrites existing sprite data. It has two implications to take into account:
- No 2 sprites being drawn with a move operation may overlap, so analysis is required to determine which sprites of a frame should be drawn using move
- A move operation implicitly clears the area its being drawn to, thus may reduce the number of required clears
This would make our flow of drawing a frame as follows:
- draw a subset of the sprites for this frame using move
- clear the remainder of the frame
- draw the remaining sprites for this frame using or
Crunching the solution space
In order to do the analysis to find the number of sprites we can move in, such that they dont overlap AND to combine this result with the analysis to maximize the reduction of using clearing of the previously drawn frame, I wrote some tooling to help me find solutions that fit those conditions. My general approach was as follows:
- I am using double buffering in the democode, so to quantize the number of clears saved, I would draw frame n-2 on the background; and plot the n-th frame onto this using the sprites with the move instructions. This way I could measure the number of clears initially required to clear frame n-2, and calculate the number of clears saved by determining the overlap of the drawn sprites OVER the n-2 frame.
- To figure out collision detection for the diffent sprites candidate for the move-drawing algorithm, I used specific masks for each seperate sprite x-position bounding box. Because the sprite is drawn with move instructions, the drawing always affects 16 pixel blocks per time; yet not every 16 pixel block is touched when drawing a sprite. Masks displayed below for positions 0..15:
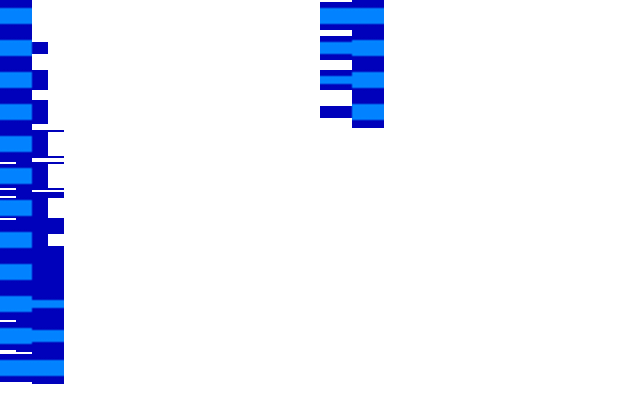
- I used a visual representation, by generating each of the 360 frames of the sprites waveform in order to do visual inspection, as well as to provide some practical overview of what my solution would look like. I did both the analysis of the frames, as well as generating the visual representation using PHP on a modern PC.
By using metrics to determine if one solution is better than the other, I was able to bruteforce a bunch of solutions for each frame and basically take the most optimal one. Aside from the actual data used to make the actual sprite record demo, the output of my data analysis looks like:
![]()
The sprites displayed each frame are the sprites that remain from the n-2'th frame (due to double buffering), and that need to be cleared. The red masks are the masks as displayed above, that represent the `most optimal solution found so far' of sprites to be drawn using move instructions for this frame.
The metrics, from left to right:
- move (green): number of sprites using move, instead of or out of the total number of sprites
- before (red): number of blocks to clear, originally
- after (blue): number of blocks to clear, when the sprites when using move for sprites
- profit (green): number of clears saved
- fm (blue): frame number out of the total number of frames
Considering I am using a (stupid) brute force approach, and the number of combinations for each solution is huge, I know fairly certain that my dataset used for my sprite record demo, is certainly not the most optimal one. But I guess, that the margin between the most optimal solution, and the one I found, would not make up the gap between Leonards 312 and my 268 sprites.
With 268 sprites, it would get down to around 598 cycles per sprite, whereas Oxygene's is at 514 cycles per sprite...
So I wondered what the next big improvement step should be.
One day Leonard, one day!
Im fairly certain that I could have dragged a few more sprites out of my current approach;
- I currently `nop' out about 2 to 3 scanlines worth of CPU time, I could have used this for drawing at least one more sprite :)
- I have about 30kb memory that can be spend towards using a more CPU-friendly datastructure or using explicit instructions (single clear operations f.e.)
- By actually implementing a smart search algorithm for the optimal solution, may have saved me a sprite or so
But it is clear that this effort would not yield the 40-odd needed sprites to usurp the current record holder. So, something must be missed out on. And after nosing around a bit, it dawned on me...
Many, many sprites overlap. One way to get advantage out of this, is to distribute the sprites in two buckets,
- drawing by move
- drawing by or
But instead of focusing which sprites do NOT overlap, and place these in the move bucket; we can also determine which sprite DO overlap. To then determine, which sprites have to be drawn completely, and which sprites do NOT have to be drawn completely, because the appropriate pixels that make up the complete sprite, have already been drawn... And this is what Leonard has done in order to get ot the 312 sprites per frame, two additional buckets...
- drawing by or top partial
- drawing by or bottom partial
And this is the next level step to come to par with the current sprite record giants!
Final words on sprite record (for now!)
On top of doing the hard analysis of the data crunching, one thing not mentioned to a big extend here, is the tradeoff between datastructures used to run the code. And generally the tradeoff is; the number of cycles saved in CPU time, comes from either larger code, or a larger (more redundant) data set. Adding additional differnet cases (partially drawn sprites, and in how many variations), will have direct impact on what kind of data structures you can employ in your code, and still remain under the 512kb memory limit. And smartly encoding data, to keep the data footprint down, will come again at a cost of cycles for decoding the data. In the end, it starts to become more of a compression problem (in a way) for a single task animation player, than a drawing sprites problem.
Its this interesting tradeoff between the various approaches that together make the most optimal solution. I have a strong belief that there is a single mathematical solution that can be proven to be the most optimal one, given the constraints imposed on us for this sprites challenge. However, I have (not by a long shot), been able to approach it in this elegant matter. I have come this far by going on my gut feeling, some guestimation, and a lot of blood sweat and tears.
For me, my explorations have led me to here. For now, the motivation to continue working on the frame analyzer and databuilder is lacking. I rather put the time and effort trying to share my discoveries done during my exploration of the sprite record rabbit hole. And considering its an intriging one, I am fairly certain that I will come back to it, one day...
So one day Leonard... One day!
And in the mean while, Atari coders out there, go have a stab at this topic!
Spkrites! sourcecode and all code referenced to in this article can be found at bitbucket.

Questions, feedback or anything else; please contact me at spkr [at] smfx.st.